Method
We argue that frames over a larger range should be considered to execute DDIM inversion. However, using all video frames directly will bring unacceptable complexity. To deal with this, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion method. The insight behind this is massive intra-frame and inter-frame redundancy lie in a video, thus there is no need to treat every pixel in the video as reconstruction bases. Then, we use the EM algorithm to find a more compact basis set (e.g., 256 bases) for the input video.
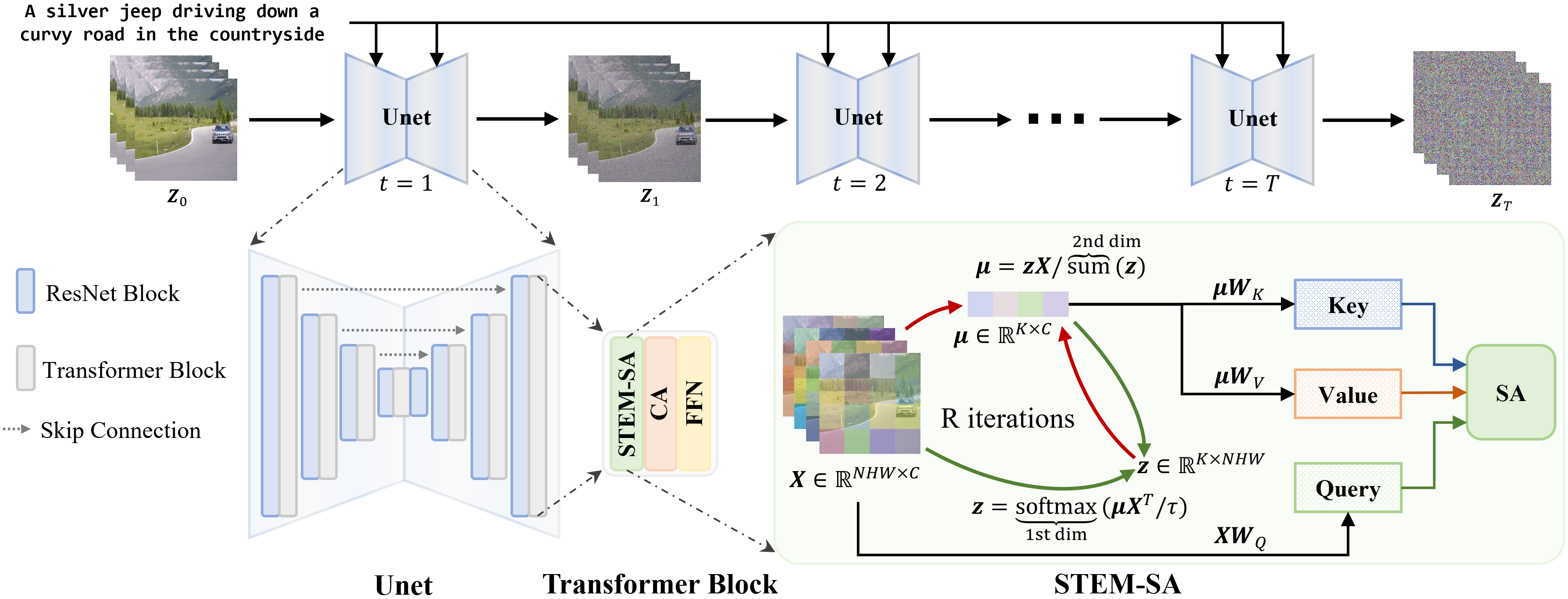 The illustration of the proposed STEM inversion. We estimate a more compact representation (bases $\mu$) for the input video via the EM algorithm. The ST-E step and ST-M step are executed alternately for R times until convergence. The Self-attention (SA) in our STEM inversion are denoted as STEM-SA, where the $\rm{Key}$ and $\rm{Value}$ embeddings are derived by projections of the converged $\mu$.
The illustration of the proposed STEM inversion. We estimate a more compact representation (bases $\mu$) for the input video via the EM algorithm. The ST-E step and ST-M step are executed alternately for R times until convergence. The Self-attention (SA) in our STEM inversion are denoted as STEM-SA, where the $\rm{Key}$ and $\rm{Value}$ embeddings are derived by projections of the converged $\mu$.
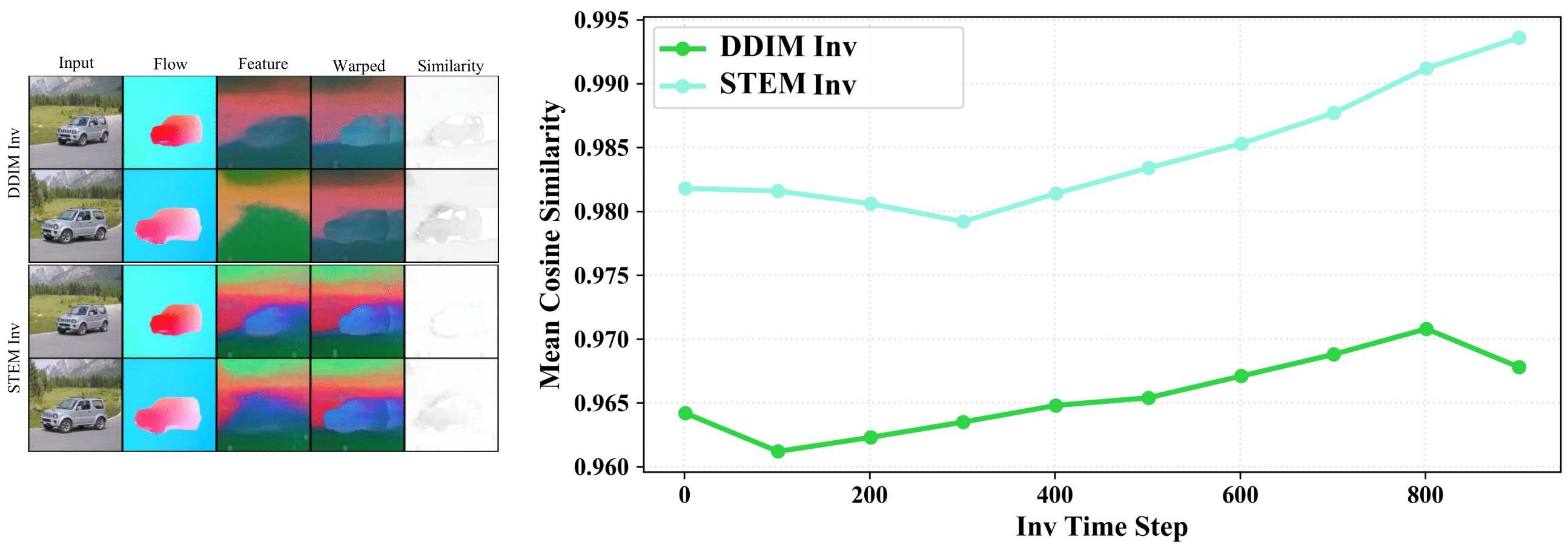 Left: we first estimate the optical flow of the input sequence. Then, we apply PCA on the output features of the last SA layer from the UNet decoder. The 4-th column shows the feature visualization when we use optical flow to warp the former-frame features. Last, we give the cosine similarity of the warped features and the target ones. Here, the brighter, the better.
Right: we provide the mean cosine similarity across different time steps. The higher similarity
indicates that our STEM inversion can achieve better temporal consistency from the perspective of optical flow.
Left: we first estimate the optical flow of the input sequence. Then, we apply PCA on the output features of the last SA layer from the UNet decoder. The 4-th column shows the feature visualization when we use optical flow to warp the former-frame features. Last, we give the cosine similarity of the warped features and the target ones. Here, the brighter, the better.
Right: we provide the mean cosine similarity across different time steps. The higher similarity
indicates that our STEM inversion can achieve better temporal consistency from the perspective of optical flow.